
By Vivian Ng
‘Man Vs. Machine’. ‘How algorithms rule the world’. ‘How algorithms rule our working lives’. ‘How Machines Learn to be Racist’. ‘Is an algorithm any less racist than a human?’ ‘Machine Bias’. ‘Weapons of Math Destruction’. ‘Code-Dependent’. These are some of the recent headlines about the age of artificial intelligence, that seem to foreshadow a not-so-promising future for the human race in its rapid advancement. One thing is clear, algorithms have become increasingly prominent in our everyday lives. What is less clear is what we can do about that and deal with both the opportunities and risks it brings.
Algorithmic accountability is currently a topical issue in the space where discourse about technology and human rights intersect. As part of its work on the analysis of the challenges and opportunities presented by the use of big data and associated technologies, the Human Rights, Big Data and Technology Project is looking into the human rights implications of algorithmic decision-making. We contributed written evidence to the UK House of Commons Science and Technology Committee inquiry on ‘Algorithms in decision-making’. The submission outlined when and how discrimination may be introduced or amplified in algorithmic decision-making, and how the various stages in the algorithmic decision-making process offer opportunities for the regulation of algorithms to prevent and/or address potential discrimination. We were also at RightsCon 2017, discussing these precise issues. We followed the track on Algorithmic Accountability and Transparency, and also organised a panel discussion on ‘(How) can algorithms be human rights-compliant?’ We gained new insight and ideas from the experts who joined us. This post sets out some of our preliminary thinking, the issues we are working through from an inter-disciplinary perspective, and some critical questions to be addressed.
Generally understood as a method or technique for making decisions, algorithms are not new. What is new is the unprecedented computational power of our machines; the availability and accessibility of data in the digital age; and continuously improving artificial intelligence. Algorithm decision-making processes can be semi- or fully-automated, which varies the extent of human influence in the actions that follow from the outcomes an algorithm generates. These algorithmic systems can offer significant benefits by increasing the efficiency of decision-making. However, there are certain risks, some of which have only started to be apparent.
Algorithmic discrimination is a key problem that has been discussed extensively in this area. (See this White House report, this Federal Trade Commission report, this UK Information Commissioner’s Office report, and ProPublica’s work on this.) Discrimination can be introduced and amplified by algorithmic decision-making – the challenge is how can we detect it, respond to it, or ideally, prevent it in the first place. To be clear, human decision-making is not without flaw or bias and that is not the question of contention here. What is problematic is the presumed objectivity and neutrality of algorithmic systems. Mathematics may be neutral in theory, but the application of mathematics in algorithmic models involves assumptions and data inputs, amongst other things, that can embed bias into the algorithmic decision-making process.
To begin working out those answers, we started by mapping out how the algorithmic decision-making process works, so we can distil the process and pinpoint the points at which discrimination can occur, and how it does. For illustration, this is the model that we sketched:
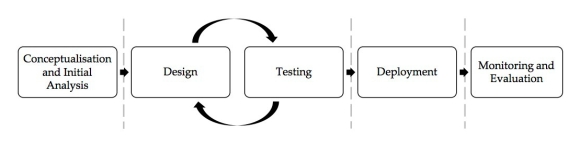
These five stages are generally the phases involved in an algorithmic decision-making process, which can take place entirely internally within the corporate structure. For example, if a company has the resources (such as data scientists and other computational experts) to design and test an algorithmic model, this would not be outsourced to protect the proprietary knowledge and unique product offering.
Conceptualisation and initial analysis involves the identification of a specific problem that an algorithm is intended to solve and the context that it will be used in. The algorithm will then be designed and tested, in an iterative process, to refine the algorithm before it is deployed, or simply, used as it was originally intended. Subsequently, consistent and sustained monitoring and evaluation ensures the performance of the algorithm and troubleshoots any problems.
Discrimination can be a problem at any and all of these stages, and importantly, if it is introduced at an early stage of the algorithmic decision-making process and not rectified, its effects can be amplified as it flows through the algorithmic system. Discrimination could occur because the algorithmic model has been designed to differentiate and sort data in a certain way, that results in indirect discrimination. Discrimination could also occur because of biased data inputs or poor quality data.
The greater challenge is in trying to increase transparency and achieve accountability through regulatory oversight. Transparency and accountability must be considered at each stage and in the algorithmic decision-making process as a whole as they are crucial to identifying problems and more sophisticated responses are required for more effective solutions to operationalise principles such as transparency, and to resolve apparent tensions with proprietary privilege.
Underlying this is the thorny and abstract question of the role of human influence in the algorithmic development and monitoring process. In a time where machines have been built to learn on their own, and could far surpass human intelligence, what limits are there to the capacity for humans to effectively regulate algorithmic decision-making processes? Can we reasonably expect and design algorithmic models to explain themselves? What role is there for machines to self-regulate?
Disclaimer: The views expressed herein are the author(s) alone.
